Random
Randomly samples a set of controls to apply each 1-3 seconds.
Learning strategic robot behavior---like that required in pursuit-evasion interactions---under real-world constraints is extremely challenging. It requires exploiting the dynamics of the interaction, and planning through both physical state and latent intent uncertainty. In this paper, we transform this intractable problem into a supervised learning problem, where a fully-observable robot policy generates supervision for a partially-observable one. We find that the quality of the supervision signal for the partially-observable pursuer policy depends on two key factors: the balance of diversity and optimality of the evader's behavior, and the strength of the modeling assumptions in the fully-observable policy. We deploy our policy on a physical quadruped robot with an RGB-D camera on pursuit-evasion interactions in the wild. Despite all the challenges, the sensing constraints bring about creativity: the robot is pushed to gather information when uncertain, predict intent from noisy measurements, and anticipate in order to intercept.
We approach this problem using privileged learning. The key to our approach is to leverage a fully-observable policy to generate supervision for the partially-observable one. During privileged training, we leverage a new type of privileged information: the future state trajectory of the evader.
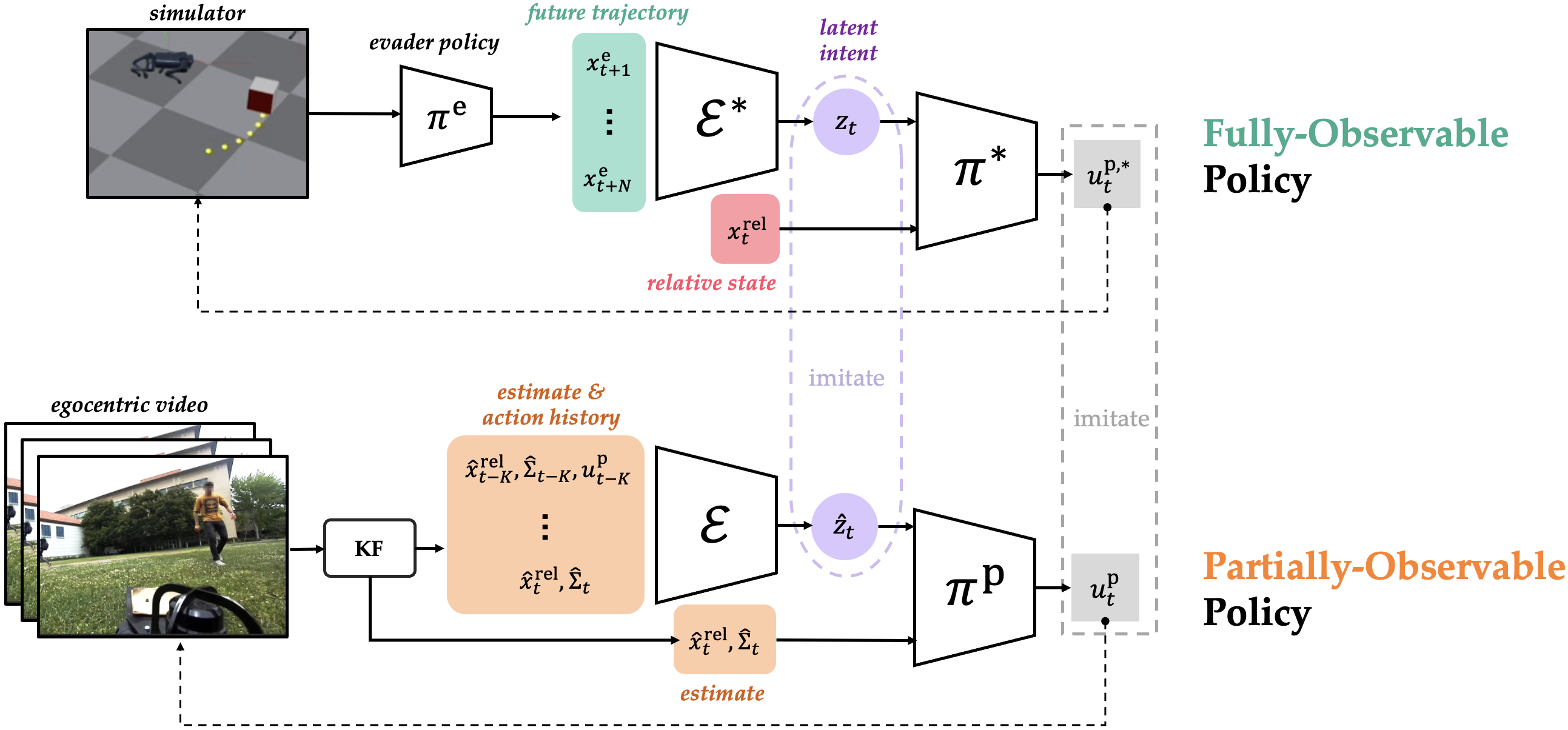
(top) The fully-observable policy knows the true relative state and gets privileged access to the future evader trajectory from which it learns a representation the evader intent. (bottom) The partially-observable policy must plan through physical and latent intent uncertainty.
In our supervised learning framework, we find that the quality of the supervision signal depends on a delicate balance between the diversity of the evader's behavior and the optimality of the interaction.
We explore three different evader models--Random, MARL, and Game Theory--that vary along the spectrum of extremely diverse to extremely optimal behavior. We train one (fully-observable) supervisor robot policy against each distribution of evader behavior. We discover that fully-observable robot policies obtained under strong modeling assumptions (e.g., both agents play under perfect-state Nash equilibrium), are less effective at supervising partially observable ones.
Randomly samples a set of controls to apply each 1-3 seconds.
Trained to evade a pre-trained pursuer policy, similar to 1-iter of prior work.
Uses state-feedback policy computed via off-the-shelf dynamic game solver.
We ablate the pursuer policy and deploy Random, MARL, and Game-Theory pursuer policies on a physical quadruped robot to interact with a human.
We observe that Random and MARL perform qualitatively similarly: they demonstrate information-seeking motions when the evader is not in the field of view and predictive strategies when the evader is visible, i.e., heading towards where the evader will be, not where it is. Conversely, Game-Theory shows inefficient information-seeking motions, taking long detours to reach the evader.
Real-world interactions are out-of-distribution for two main reasons: (1) the behavior of the evader is unscripted and possibly very different to what was observed in simulation, and (2) the physical dynamics of the evader do not follow the unicycle dynamics model as in simulation.
We deploy our policy zero-shot on a physical quadruped robot equipped with an RGB-D camera in unscripted pursuit-evasion interactions. We vary the type of agent the autonomous robot inteacts with from a human to another quadruped teleoperated by a human, and deploy in a variety of unstructured environments like a eucalyptus forest, grassy fields, and brick roads.
Top-down drone footage of human-robot interaction.
Raw video stream from robot's onboard RGB-D camera.
Robot pursuer predicts where the person will run despite the eucalyptus tree obstacles.
Multiple humans can play a game of tag with the robot. The robot quickly switches which human it intercepts based on who is in the FOV.
Since the human starts outside the FOV of the robot, the robot turns and seeks until it gets the first detection. The robot predicts the human will go straight and gallops to where the person will be. The human then strategically hides outside robot's FOV to escape.
The human accelerates and swerves to trick the robot. The robot anticipates the serve and keeps the human in its FOV.
The black A1 robot is autonomous, running our Random policy and plays the role of the pursuer. The silver Go1 robot is teleoperated by a human to play the evader.
Early on, the pursuer predicts and intercepts the evader. The game continues and the evader swerves, hiding outside the pursuer's FOV. The pursuer robot automatically turns and seeks the puruser.
Pursuer predicts the evader's motion, but misses interception.
@article{bajcsy2023learning,
title={Learning Vision-based Pursuit-Evasion Robot Policies},
author={Bajcsy, Andrea and Loquercio, Antonio and Kumar, Ashish and Malik, Jitendra},
journal={arXiv preprint arXiv:2308.16185},
year={2023}
}